
Many startups operate under a common assumption: build fast, validate the idea, and worry about scale later. Speed does matter. But ignoring scalability entirely often becomes one of the most expensive mistakes a growing company can make.
An MVP gains traction. Users grow faster than expected. Performance declines. Shipping new features slows down. The codebase becomes fragile. The product that proved demand becomes the barrier to growth.
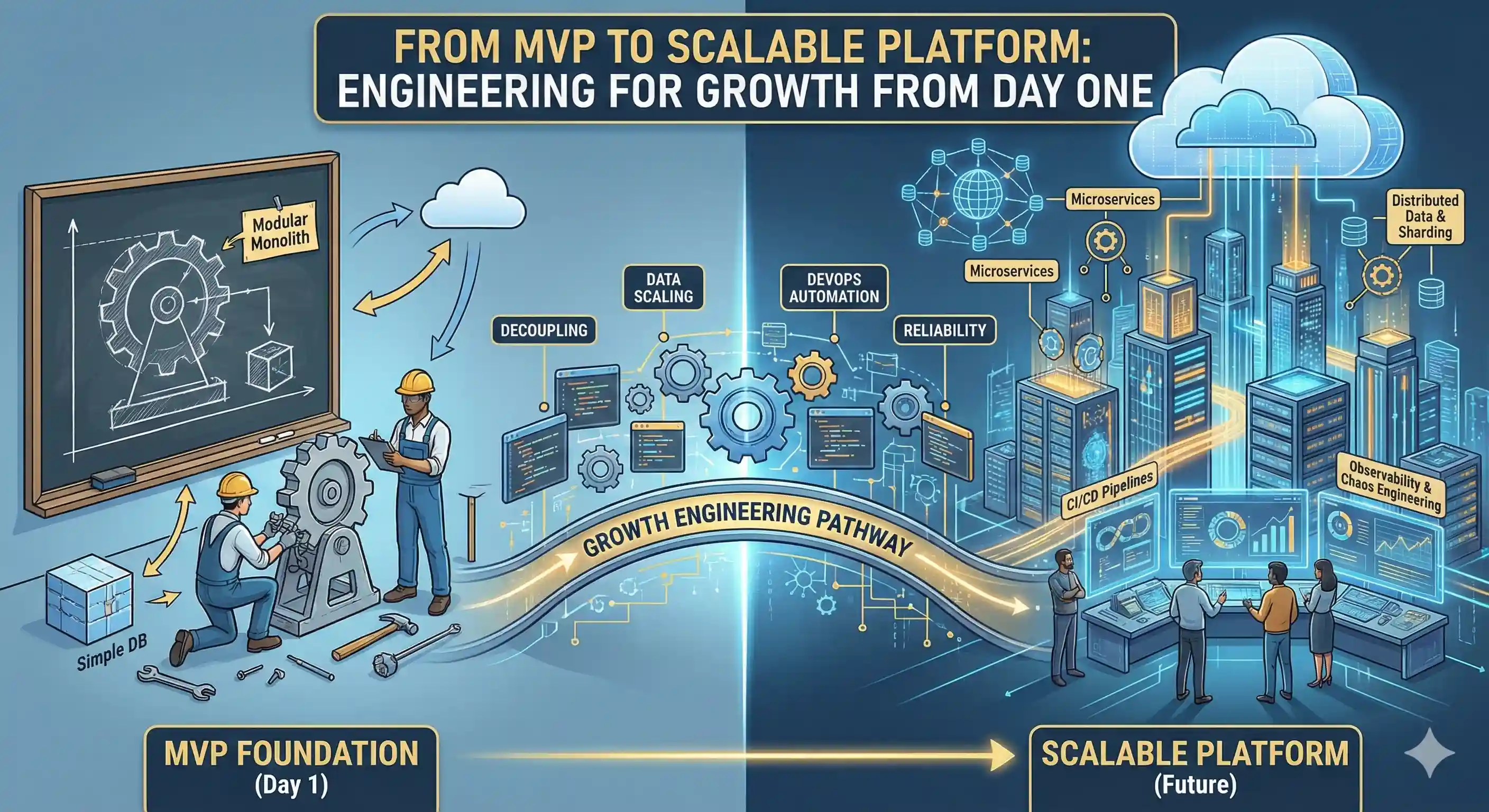
In 2026, strong engineering teams do not choose between speed and scalability. They build MVPs designed to grow without collapsing under success.
Scalability is not only about handling more users. It includes maintaining performance under load, adding features efficiently, supporting growing teams, adapting infrastructure, and controlling long-term costs.
Scalability does not mean building complex microservices on day one or overengineering early abstractions. It means establishing smart foundations that make future change easier.
Common scaling issues stem from tightly coupled code, poor separation of concerns, weak database design, hard-coded logic, and lack of monitoring.
These problems are often invisible at low traffic but compound rapidly as usage increases.
Engineering for growth is about reducing the cost of change over time.
Your MVP will evolve. Business models shift. Features expand. Customer behavior surprises you.
Code should be flexible, easy to modify, and free from rigid assumptions. Designing for change often matters more than raw performance in early stages.
Enterprise-level complexity is unnecessary for early-stage products, but structural clarity is essential.
A modular monolith often works better than early microservices. Clear domain boundaries, defined internal APIs, and loosely coupled components allow features to evolve independently.
Simplicity with structure creates long-term flexibility.
Data design decisions are difficult to reverse later.
Early schema planning, proper relationships, indexing strategies, and clear data ownership reduce future bottlenecks. Data models should reflect real business entities and support analytics and reporting needs from the beginning.
Poor data design turns growth into technical friction.
Performance optimization should be focused, not excessive.
Prioritize core user flows, API responsiveness, database efficiency, and frontend load times. Use caching, asynchronous processing, and background jobs strategically.
Measure before optimizing—but do not ignore performance until it becomes urgent.
Scaling requires visibility.
Implement logging, error tracking, performance metrics, and uptime monitoring from the start. Early observability reduces debugging time and supports better product decisions.
Adding monitoring later is significantly harder and riskier.
Cloud-native hosting, infrastructure as code, environment separation, and automated deployments create a stable foundation for scaling.
Automated systems support faster releases, safer updates, and elastic scaling under load.
Manual infrastructure management does not scale effectively.
Technical debt is unavoidable. Unmanaged debt is dangerous.
Document shortcuts, track known limitations, and schedule refactoring intentionally. Engineering for growth means controlling debt rather than ignoring it.
As products grow, teams expand.
Clean code organization, consistent patterns, documentation, and clear ownership allow new developers to onboard quickly. If only one person understands the system, scaling becomes fragile.
A fragile MVP is fast but brittle, tightly coupled, and difficult to extend.
A growth-ready MVP is modular, performance-aware, clearly structured, and designed for iteration.
The difference is not speed—it is intention.
Scalability should be considered earlier than most founders expect.
You do not need to build for millions of users immediately, but you should avoid architectural decisions that prevent growth beyond early traction.
Early questions matter: Can this design handle 10x usage? Will feature development accelerate or slow down? Can new developers contribute quickly?
KentaurX builds MVPs designed for long-term growth.
Our approach combines modular architecture, scalable data design, clean code structure, cloud-native infrastructure, automated deployment pipelines, and continuous performance optimization.
The objective is not only to launch—but to scale without reengineering under pressure.
Explore scalable platform engineering with KentaurX
Overengineering is premature. Thoughtful foundations are not.
Refactoring under growth pressure is significantly more expensive and disruptive.
In most cases, a well-structured modular monolith scales further than expected and keeps complexity manageable.
When implemented correctly, it accelerates long-term velocity by reducing future friction.
No. Any digital product expecting user growth benefits from scalable foundations.
Speed brings products to market. Scalability keeps them competitive.
Engineering for growth is not about predicting every future need. It is about preserving flexibility and preventing success from becoming a bottleneck.
When an MVP is built intentionally, growth becomes opportunity—not crisis.

Whatsapp: +91 93618 97364
Email: We@kentaurx.com